
Après le Green Washing et l'IoT Washing, n'est-on pas face à du AI Washing. De nombreuses entreprises en particulier des startups se prévalent d'intégrer de l'intelligence artificielle, en font-elles vraiment et n'y a-t-il pas de fausses promesses derrière ?
For English Speakers - Google Translation
N'y a-t-il pas des risques à utiliser de l'IA sans comprendre les impacts ? Est-ce que les réseaux neuronaux sont la panacée pour résoudre tous les problèmes ou au contraire ne nous mènent-ils pas vers une impasse en étant une boîte noire ? Est-ce que l'IA est robuste ou au contraire un géant à pied d'argile ? Qu'en est-il de l'IA forte qui supplanterait les hommes ?
Il y a encore du chemin avant qu'une IA soit capable de rivaliser avec un être humain de manière complète. Le "Gift Test", test du cadeau (capacité d'une IA à faire plaisir à une personne en lui faisant un cadeau) serait un bon indicateur de l'avancée de l'IA. On pourrait bien sûr inverser la situation de la photo, un homme à la place de la femme et un robot à l'apparence féminine et non masculine (ou encore homme/robot apparence homme ou femme, robot apparence femme), l'objectif de cette photo est d'illustrer le challenge pour un IA d'intégrer et d'anticiper la réaction de l'autre sans avoir la possibilité de la tester au préalable.
Cet article a pour but de couvrir ces différents thèmes, il sera décomposé en trois parties. Dans cette première, j’aborderai l’intelligence artificielle de manière générale et je ferai un focus sur les réseaux neuronaux, ses limites et comment rendre explicable les réseaux neuronaux...
(Pour avoir des sensibilisations, formations même à distance, sur l’IA, la "data", générales ou liées à votre secteur, vous pouvez me contacter ici : [email protected] ou ici ). Nous menons aussi des projets sur l'IA et la data, l'IoT notamment.)
Il y a aussi d'autres types d’IA (réseaux bayésiens, algorithmes génétiques, logique floue, systèmes multi-agents ...) et d'autres problèmes, interrogations posés par l’IA pour notre société (de l'ANI - IA faible à l"ASI - IA dépassant tous les hommes ("Singularity") en passant par l'AGI, équivalent à l'IH, intelligence humaine, les risques sur la perte de créativité et la normalisation...) .
En bref, cet article-ci couvre :
- Préambule sur l’AI Washing
- Définition de l’intelligence artificielle
- Différence entre l’IA perceptive / d'interface et IA décisionnelle
- Decryptage des réseaux neuronaux
-
- Qu’est-ce que le Machine learning, Deep learning ?
- Les problèmes posés par les réseaux neuronaux
-
- Problèmes de la boîte noire (et explainable AI), de la non-détection de cas exceptionnels, cygnes noirs
- Nécessité de règles claires (IA face aux jeux : évolution d'AlphaGo de DeepMind du Go à Starcraft II)
- Manque de priorisation a priori et les problèmes de biais de confirmation
- Système faillible/hackable avec des backdoor mais non auditable (notamment en open-source)
- Solutions potentielles :
-
- Comment contourner ces problèmes et auditer / rendre explicable un réseau neuronal ? (Adversarial AI / Explainable AI en utilisant des random forests)
- Comment accélérer l'apprentissage avec la vectorisation des images / données initiales
- Conclusion
Préambule sur l’AI Washing

Entre nous, qu’une startup fasse ou pas de l’IA n’est pas ce qu’il y a plus important voire pire pourrait vous alerter, l’IA est un moyen et non une fin.
La question principale est pourquoi font-ils de l’IA ? Est-ce qu’ils sont plus rapides à répondre, plus fiables, capables de couvrir un champ plus large, de donner des données introuvables autrement ou d’intégrer plus de données ? Quels sont les biais potentiels lorsqu’ils utilisent leur IA ? Peut-on expliquer les choix réalisés par leur IA (Si une startup vous dit qu’ils utilisent des réseaux neuronaux pour leur IA et qu’ils sont capables d’expliquer les décisions prises par cette IA … Il y a un petit souci, soit ils ne font d’IA soit ils en utilisent, mais ne la comprennent pas ou pire … )
Souvent des algorithmes simples auditables sont beaucoup plus efficaces qu’un réseau neuronal boîte noire dont on ne peut prédire de manière certaine les résultats. Pour donner quelques exemples, les statisticiens connaissent des tests comme
- l’analyse multi-variée (très utilisée dans les sondages pour connaître la contribution de facteurs implicites dans une satisfaction globale),
- le test de la médiane de Mood (fondé sur les écarts entre deux groupes de données sur base de la médiane (50% donc beaucoup moins sensible aux valeurs extrêmes) plutôt que la moyenne),
- les modèles de CHAID (technique de type arbre de décision fondée sur Chi2 pour sélectionner par exemple un groupe de consommateurs et prédire comment leurs réponses à certaines variables affectent d'autres variables),
- les plans d'expérience ( qui est une version multi-variables du test A/B et permet de mesurer des relations de cause à effets) …
- et encore plein d'autres
Cela vous permet avec relativement peu de données comparées aux réseaux neuronaux de relever des différences significatives entre des groupes de données de les catégoriser, classifier, déterminer les principaux facteurs de variation et les corrélations, des relations de cause à effets... … Ces outils statistiques peuvent aussi servir de première base de travail pour l’IA (ex : pour créer un arbre de décision).
Définition de l'IA - intelligence artificielle

Il y a de multiples définitions de l'IA, selon Wikipedia, c’est « l'ensemble de théories et de techniques mises en œuvre en vue de réaliser des machines capables de simuler l'intelligence ». Certains illuminés diront que c’est une pensée magique hors de la compréhension humaine, que des mauvaises langues traduiront par un ensemble d’algorithmes et d’opérations que l’intelligence humaine ne peut pas comprendre. Nous ne sommes pas loin du transhumanisme ...
C'est John McCarthy qui l'a défini en premier en 1956, comme "the science and engineering of making intelligent machines". Grosso modo, John nous a sorti une définition de ce qui est artificiel, c’est-à-dire une machine et non une définition de l'intelligence artificielle ;)
L'IA est le Canada Dry de l'intelligence humaine, cela ressemble à de l'intelligence humaine, mais ça n'en est pas vraiment.

Opposer l’IA de l’intelligence humaine uniquement par son caractère non humain est pour moi, beaucoup trop réducteur.
A titre personnel, je pense que c'est une erreur de réduire la définition de l'IA à une IH (intelligence humaine) qui n'en est pas, car cela génère tous les biais, généralisations, anthropomorphismes erronés et en premier cela oppose IA à IH alors qu’elles peuvent être complémentaires.
D’autres définitions décrivent l’IA par ce qu’elle contient, des poupées russes, une grande intégrant des systèmes experts / de règles, une plus petite avec du machine learning (système apprenant par elle-même ses règles) puis du deep learning (lié aux réseaux neuronaux cf. ci-dessous).
L'intelligence selon Platon

On oublie sans doute de définir d'abord ce qu'est l'intelligence.
Selon les Définitions de Platon, l’intelligence est l' «activité qui permet d’acquérir la science»
Selon Wikipedia, l'intelligence est l'ensemble des processus de pensée d'un être vivant qui lui permettent de comprendre, d'apprendre ou de s'adapter à des situations nouvelles. C'est une faculté d'adaptation (apprentissage pour s'adapter à l'environnement ou au contraire, faculté de modifier l'environnement pour l'adapter à ses propres besoins).
L'intelligence peut être également perçue comme la capacité à traiter l'information pour atteindre ses objectifs. Le terme est dérivé du latin intelligentĭa, « faculté de comprendre », dont le préfixe ĭnter- (« entre »), et le radical legĕre (« choisir, cueillir ») ou ligāre (« lier ») suggèrent essentiellement l'aptitude à lier des éléments entre eux, à faire preuve de logique, de raisonnement déductif et inductif.
IA nécessite la faculté d'apprendre pour des êtres non vivants

Pour ma part, j’ai aussi ma petite définition de l'IA
C’est la faculté d'apprendre à transformer des données complexes et variées en décisions simples et pertinentes… pour des êtres non-vivants.
Je préfère dire ici "faculté d'apprendre" que "faculté de s'adapter", on pourrait avoir un système qui s'adapte, mais qui n'apprend pas (pour pousser un peu le raisonnement, l'eau liquide s'adapte à toutes les formes, mais n'apprend pas ;)
IA : finalité externe (venant de l'homme mais pas que...) - IH - finalité interne

D’autre part, selon moi, les êtres vivants se caractérisent par le fait qu'ils aient une finalité (consciente ou non) (par exemple survivre et se perpétuer).
Aujourd’hui, la finalité d’une IA vient de l’extérieur et non de l’intérieur, c’est l’homme qui la lui donne, mais on pourrait imaginer qu’un animal voire une plante transmette sa finalité à une IA (se perpétuer) et qu’elle l’aide à se nourrir, à se perpétuer … (exemple d'expérience : confronter une IA à une souris dans un labyrinthe géré par cette IA via des portes coulissantes donnant accès à de la nourriture. La survie de l'IA serait directement dépendante de celle de la souris. On pourrait même introduire plusieurs souris...).
Je pousse encore plus loin, une IA pourrait même tirer sa finalité et apprendre d’un environnement extérieur non vivant (observation des vagues de la mer, des transformations d’une montagne au cours des saisons, cycle d'un écosystème )… La survie de l'IA pourrait dépendre de la pérennité de l'écosystème (équilibre de la température, du taux de CO2...). En revanche, il y a au départ une intelligence humaine qui indiquera à l’IA d'où elle devra tirer sa finalité et apprendre à partir d’autres êtres vivants, de l’observation de la Nature…
J'ai une vision aristotélicienne à ce sujet : notre téléologie / finalité est intrinsèque (le "telos" est un principe de développement immanent et interne à tout être naturel).
Une IA n’a pas besoin de finalité pour survivre à la différence des êtres humains en revanche et des autres êtres vivants. Est-ce à dire qu’un homme qui deviendrait immortel perdrait sa finalité …
Après, rien ne nous empêche de revenir à Platon et de croire à une téléologie/finalité extrinsèque qui proviendrait d'un démiurge (une des idées de Elon Musk qui pense très probable et préférable que nous fassions partie d'une simulation et donc notre finalité pourrait être extrinsèque et non intrinsèque), mais alors qu'est-ce qui nous différencierait alors encore d'une IA ...
Bon, je vais arrêter de spéculer sinon je vais vous perdre définitivement ! (même si les thuriféraires et pourfendeurs de l'IA devraient se replonger dans la philosophie, un des rares métiers qui restera longtemps l'apanage des êtres humains ;)
IA perceptive et décisionnelle

Il y a aussi de nombreuses manières de classifier l'IA en fonction de sa finalité, de son fondement mathématique, de la taille de son spectre ....
Aujourd'hui, les principales applications massives de l'intelligence artificielle sont dans la perception de son environnement, les images, les vidéos, la reconnaissance vocale, d'écriture, de texte (text mining), mais ça pourrait s'appliquer aussi notamment avec l'Internet des Objets dans la perception de matériaux, d'aliments, d'odeurs... sur base de leur signature chimique, spectrale...
Les applications concrètes de l'IA dans la prise de décision sont comparativement encore peu visibles (mais cela évolue très rapidement). Son impact sur nos vies quotidiennes sera nettement plus important que l'IA perceptive, c'est là où résident toutes nos peurs et tous nos fantasmes (cf. article sur les armes autonomes, décisions juridiques...) avec cette peur ultime d'être mis au rebut par une IA supérieure...
Pour donner un exemple concret, un véhicule autonome utilisera l'IA perceptive pour visualiser les autres automobilistes, panneaux de signalisation, piétons ...C'est l'IA décisionnelle qui prendra la décision de freiner, de changer de voie et potentiellement de faire le choix de sauver la vie du conducteur ou de sauver la vie des deux enfants et trois mamies qui se trouvent face à lui.
IA décisionnelle et le paradoxe du véhicule autonome
Pour l'anecdote, j'ai vu une étude où on demandait aux personnes quelle devrait être la réaction d’une voiture autonome face à ce choix. La très grande majorité des personnes ont dit qu'il fallait que la voiture sauve les enfants et mamies, quand on leur a demandé juste après s'ils étaient prêts à acheter ce type de voiture, ils ont quasiment tous répondu non.
Cela nous amène à un énorme paradoxe, le véhicule autonome a priori devrait sauver un très grand nombre de vies humaines (rappelons, qu’il y a eu 3477 décès en 2016 en France en raison d’accidents de la route), mais en choisissant de ne pas protéger en premier lieu le conducteur, on n'achètera de véhicules autonomes et donc au final il y aura plus de personnes victimes d'accidents de la route, conducteurs, passagers, piétons ...
Cela a d'ailleurs certainement motivé Mercedes qui a indiqué qu'il protégerait en premier lieu le conducteur. Si cela vous dit, vous pouvez passer le test réalisé par le MIT, pour voir ce que vous feriez si vous étiez à la place de l'IA (privilégeriez-vous les personnes âgées, les enfants, les piétons, les passagers, les animaux ou vous-même ?)
Autre point, ce type de dilemmes insolubles sera à mon avis rarissime comparativement à tous les accidents que nous avons aujourd'hui, mais peut nous bloquer dans l'adoption de ce type de technologies. Il est certes essentiel de se poser ces questions. C'est à la fois une bonne chose de prendre un peu de temps, car cela nous donne plus de temps de les assimiler et de décider quelles sont les règles à appliquer. Néanmoins, à un moment il faut décider, car en restant bloqué trop longtemps sur ces sujets, c'est la vie de nombreuses personnes que nous mettons en péril. Le port de la ceinture, les limitations de vitesse ... ont permis de réduire les accidents (il y avait plus de 18000 tués sur les routes en 1972 soit 5 fois plus qu'aujourd'hui), le véhicule autonome le permettra aussi certainement.
Décryptage des réseaux neuronaux

Aujourd'hui, nous parlons beaucoup des réseaux neuronaux qui simulent très grossièrement le réseau de neurones humains. En gros, si vous vous rappelez vos cours de mathématiques de Terminale, les réseaux neuronaux reproduisent la multiplication de matrices.
En gros, vous avez des matrices d'entrée (par exemple une image de chat décomposée en points avec une valeur RGB) et des matrices intermédiaires (avec des coefficients pondérateurs) qui vont la réduire (en agrégeant et sommant plusieurs données avec ces coefficients) en une probabilité entre deux choix ce soit un chat ou ce n'est pas un chat.
Machine Learning (ML dans des réseaux neuronaux)

Le machine learning couvre toutes les techniques d'apprentissage automatique. Il ne couvre pas uniquement les réseaux neuronaux mais d'autres types d'IA comme les resaeau xbayésiens, les algorithmes génétiques...
Ici, je ne couvrirai que le machine learning pour les réseaux neuronaux.
Au début, les réseaux neuronaux étaient créés manuellement, et l'apprentissage était réalisé par l'homme qui transformait ces réseaux neuronaux. Le machine learning intégré dans les réseaux neuronaux consiste à ce que cette phase d'apprentissage soit automatisée.
Pour réaliser du machine learning (sur des réseaux neuronaux), au départ, les coefficients dans les matrices/couches intermédiaires sont aléatoires. Le machine learning consiste à faire passer au crible une quantité d'images, par exemple avec un chat et d'autres sans à un réseau neuronal (donc des matrices ayant des coefficients aléatoires).
Au début, le résultat est complètement aléatoire. On peut alors comparer le résultat avec celui donné par des humains ayant qualifié auparavant ces images. Si le réseau neuronal qualifie bien l'image (au début c'est par pur hasard), un mécanisme de rétropropagation (backpropagation) qui va renforcer les "neurones" ou plus simplement les coefficients de la matrice en leur donnant plus de poids (par exemple un coefficient de 1 devient 1,5), inversement si le réseau neuronal considère que c'est un chat alors que ce n'en est pas un, il va réduire la valeur des coefficients. En faisant cela des millions de fois, on peut arriver à une matrice qui se stabilise sur des coefficients précis. La rétropropagation utilise une technique qui permet de modifier la matrice de chiffres afin de minimiser l'erreur (nommée la descente de gradient via des fonctions de dérivation partielles calculable. L'avantage de celles-ci est qu'elles sont calculables en un temps linéaire et non exponentiel). La backpropagation peut être encore optimisée en utilisant le SGD (Descente de gradient stochastique)
Néanmoins, il peut arriver que le réseau neuronal ne se stabilise pas ou atteigne des minimas locaux (il y a une meilleure solution, mais le réseau neuronal se stabilise sur une moins bonne solution). Si certains se rappellent d'autres cours de maths, c'est le même problème que les techniques de résolution d'équations et la recherche d'optima.
Le machine learning signifie que le réseau neuronal possède ce mécanisme de rétropropagation, car les coefficients vont au fur et à mesure évoluer pour se stabiliser (c'est ce qu'on appelle de l'apprentissage !).
Deep learning (DL)
Le deep learning (DL) est une technique utilisée dans le machine learning qui utilise plusieurs matrices ou couches qui vont "voir" différentes choses (cf. schéma), typiquement pour un chat cela pourra être la couleur, la forme, la position.... Yann Le Cun, nommé à la tête de FAIR (« Facebook Artificial Intelligence Research ») puis en charge de la recherche sur l'IA chez Facebook est l'origine du Deep Learning (et de quelques illustrations ci-dessous ;)
Le machine learning (avant le deep learning/DL) était initialement doté d'une seule couche, au départ c'était des hommes qui a la mano devaient créer ces matrices.

En gros, une image va passer chaque filtre (couleur, forme...), avec une probabilité d’appartenir à la catégorie "chat", en combinant les différents filtres. A la fin on sera à même de dire si c'est un chat ou pas (avec une probabilité).


De manière très schématique, c’est comme si vous aviez des tamis avec des formes différentes, des tailles différentes, seuls les objets passant l’ensemble des tamis seraient considérés comme exacts (modulo le fait qu'à la différence d'un tamis où ça passe ou pas, chaque tamis donne une probabilité de faire partie de la catégorie) .
Chaque filtre correspond à une abstraction différente de l’image (couleur, forme…). En revanche, cette abstraction n'est pas en général intelligible pour un être humain. Avant le deep learning, il y avait un seul filtre qui devait être créé manuellement et transformait une image en chat, avec le deep learning, les filtres (ou abstractions) se créent automatiquement grâce à l’apprentissage et permettent d’être beaucoup plus précis dans la détermination de l’image.
Pour citer Olivier Ezratty "le DL visuel de Google utilise 152 couches alors que l’Homme n’en utilise que 5 dans son cortex visuel. Il y a une divergence des méthodes entre l'Homme et le DL. L’Homme a un cortex visuel plat « large » et faiblement profond. Le DL de vision est plus profond que large. Par contre, l’explicabilité du DL est plus simple, en théorie, pour les réseaux récurrents et à mémoire, qui servent surtout au NLP (Natural Language Processing - reconnaissance vocale et traitement ), même si leur fonctionnement est très mal expliqué dans la littérature."
Différences spécifiques entre ML et DL
Curse of dimensionality ou fléau de la dimension

Pour l'illustrer, un extrait de wikipedia
"Leo Breiman donne l'exemple de 100 observations couvrant l'intervalle unidimensionnel [0,1] dans les réels : il est possible de dresser un histogramme des résultats et d'en tirer des inférences. En revanche, dans l'espace correspondant à 10 dimensions [0,1]10, les 100 observations sont des points isolés dans un vaste espace vide, et ne permettent pas l'analyse statistique3. Pour réaliser dans [0,1]10 une couverture équivalente à celle des 100 points dans [0,1], il ne faut pas moins de 1020 observations – entreprise gigantesque et souvent impraticable.
Le fléau de la dimension est un obstacle majeur dans l'apprentissage automatique, qui revient souvent à tirer des inférences d'un nombre réduit d'expériences dans un espace de possibilités de dimension élevée. Il devient alors souvent nécessaire d'injecter des informations a priori de manière à contraindre le système d'apprentissage pour obtenir des inférences. Il doit être préparé au type d'information à extraire. On parle alors d'inférence bayésienne."
Une des techniques pour y faire face est soit "d'aplatir" c'est-à-dire de réduire le nombre de dimensions (potentiellement en utilisant une autre IA pour identifier les dimensions les moins pertinentes et donc susceptibles d'être aplaties avec un impact réduit), soit de réduire la résolution/la précision de l'image.
Pour cela, on utilise couramment les réseaux neuronaux convolutifs (dont Yann Le Cun est à l'origine). qui est une forme de filtre d'image (utilisé dans Photoshop pour améliorer la netteté, voir les contours...). Elle va appliquer à chaque pixel une mini-matrice à chaque pixel qui va transformer l'image et réduire sa taille. C'est sur cette base que va s'entraîner le réseau neuronal (avec des images de quelques centaines de pixels de large et long plutôt que des images beaucoup plus grandes.
La dernière technique que je propose est la vectorisation des images, dont je parle ci-dessous dont à ma connaissance je n'ai pas entendu parler.
Quantité de données nettement supérieures pour le DL Vs ML
Merci à Olivier Ezratty

Je remercie beaucoup Olivier qui a lu ma première version d'article publiée et que j'ai corrigé grâce à ses retours (notamment distinction entre ML / DL, curse of dimensionality, DL visuel de l'homme et de Google). je vous conseille très fortement de lire son eBook sur l'IA (plus de 300 pages,que je vais de ce pas lire :)
Problèmes des réseaux neuronaux
Problème de la boîte noire

Le premier problème est que nous n'avons aucune idée pourquoi un réseau neuronal va considérer une image comme un chat ou pas, plus largement on ne sait expliquer pourquoi il fait tel ou tel choix sur base des données qu’il reçoit ... C'est une boîte noire ou plutôt une boîte remplie de matrices de chiffres qui n'ont pas de sens pour nous.
La Chine a décidé récemment d'utiliser des robots dotés d'IA pour désengorger ses tribunaux ses décisions judiciaires. Il a été aussi utilisé pour revoir des décisions de justice, la moitié ont été corrigées et 541 condamnations ont été commuées ...
Imaginez que l'on condamne une personne à 20 ans de prison, mais qu'on soit incapable de lui dire pourquoi, juste parce que c'est fondé sur une IA surentraînée fondée sur des réseaux neuronaux. C’est un peu gênant …

Dans le même registre, Poutine a indiqué que le pays que l’IA apporterait « des opportunités colossales et des menaces difficiles à prédire aujourd’hui et que celui qui en deviendra le leader sera celui qui dominera le monde.». Il prône aussi la guerre préventive en disant « Quand les drones d’un parti seront détruits par ceux d’un autre, celui-ci n’aura pas d’autres choix que de se rendre. », ce qui comme je l’ai dit dans un autre article présente un risque de surenchère impossible à maîtriser …
… ce qui a fait dire à Elon Musk que le danger de l’IA est plus grand qu’une bombe nucléaire provenant de la Corée du Nord et serait sans doute à l’origine de la troisième guerre mondiale.
Explainable IA

C’est une des raisons pour lesquelles, je pense, que le « buzz » autour des réseaux neuronaux devrait fort diminuer d’ici un ou deux ans pour laisser la place à l’ « Explainable IA » avec d’autres technologies d’IA comme les réseaux bayésiens, les algorithmes génétiques...
Même si, je propose ci-dessous une technique pour expliquer les réseaux neuronaux (je ne suis sans doute pas le premier à y avoir pensé ;)
Quantité de données nécessaires et non-détection des premiers cas, cas exceptionnels, cygnes noirs

Aujourd’hui, la création de réseaux neuronaux nécessite une quantité phénoménale de données et un temps d'apprentissage long (qui se réduit drastiquement néanmoins).
Une raison majeure de l’expansion des réseaux neuronaux est l’accès à des très grandes bases de données associées à la possibilité de réaliser des calculs massivement en parallèle (ex : architecture CUDA utilisée par NVidia pour ses puces GPU à la différence de puces CPU qui ont une architecture centralisée).

Lorsque les données sont accessibles ou générables automatiquement, cela n’est pas gênant. Le nouvel AlphaGo a joué contre lui-même 4,9 millions de parties et en 5 jours avant de dépasser le précédent AlphaGo qui a battu le champion du monde de Go, Ke Jie.
Il a appris par lui-même (sans historique préalable ou d’aide humaine).
Les cas où il y a très peu de données
Dans des domaines comme la santé, cela veut dire transmettre une quantité d'informations énormes qu'on ne souhaite pas particulièrement transmettre. Tous les cas exceptionnels comme les maladies orphelines ne pourront être traitées à ce jour par les réseaux neuronaux en raison du manque de données.
Les cygnes noirs (catastrophes climatiques, tremblements de terre inattendus, crises financières…) sont aussi très difficiles à prévoir. Un réseau neuronal n’aurait pas été entraîné pour les détecter comme ils ne sont jamais apparus auparavant et donc par définition ne pourra les prévoir.
Même si l’accès à de très nombreuses données devient de plus en plus facile (accéléré par l’IoT ;), il y a de nombreux cas où le jeu de données est très faible et où vous ne pouvez pas tester une multitude de situations automatiquement (comme l'a fait AlphaGo en jouant contre lui-même). Même si la robotique devrait permettre notamment dans la biologie, la génétique d'avoir accès à de plus en plus de données. Par exemple, Eligo Bioscience, fondé par Xavier Duportet n'utilise pas aujourd'hui l'IA pour développer des biothérapies programmables au monde pour le microbiome. Imaginez que vous utilisez des cobots (robots collaboratifs) pour réaliser des tests biologiques en intégrant de l'IA pour faire des plans d'expérience et identifier les biothérapies le plus adéquates... En revanche, vous ne construirez pas de réseau neuronal sur base de tests cliniques avec des patients humains !

Dans d'autres domaines, une négociation commerciale en gré à gré (hors transactions standardisées), comprendre les réactions et les émotions de quelqu’un, savoir ce qui est juste ou non (différent de ce qui est légal ou pas qui est codifié et relatif en fonction des cultures, histoires de chacun…) sont autant de domaines qui ne permettent un test massif de données.
Ce problème pourrait être partiellement résolu si l'on trouve des solutions pour réduire drastiquement le besoin de données (un des axes majeurs de recherche de Yann Le Cun de Facebook) pour créer des réseaux neuronaux, d’autre part il y a d’autres systèmes comme les réseaux bayésiens, les réseaux multi-agents ... qui alimentent l’IA et nécessitent beaucoup moins de données.
Néanmoins, pour faire une analogie quantique (on en revient toujours au chat ... de Schrödinger), un des challenges de l'IA est que le test d'une hypothèse peut nous empêcher de la retester dans les mêmes conditions ou comme dirait Coco Chanel "Vous n'aurez pas deux fois l'occasion de faire une première bonne impression".
Enfin, s'il résout déjà les problèmes concernant un grand nombre de personnes où les données sont nombreuses, cela est déjà utile !
Règles claires nécessaires - des échecs à Starcraft
Echecs

Les réseaux neuronaux ont fortement évolué. Deep Blue a su battre Gary Kasparov aux échecs en 1997 qui est un jeu qui présentent un nombre élevé de possibilités mais accessible à l’époque (1,5^118 combinaisons – 30 possibilités de mouvement par joueur en moyenne et 40 coups par joueur) selon le mathématicien Claude Shannon.
En revanche ce n’était pas de l’IA mais de la « force brute», le super ordinateur calculait de 6 à 20 coups à l’avance ce qui lui a permis de prendre le dessus sur Kasparov.
Go

Le go se joue sur un Goban de 19x19 (soit 361 cases au total), il est possible de jouer 361 combinaisons, soit 1,4 x 10^768 coups soit beaucoup plus que les échecs. Aujourd’hui, un ordinateur ne pourrait traiter l’ensemble des combinaisons.
AlphaGo développé par Deepmind (racheté par Google) utilise des techniques d’apprentissage supervisé (en intégrant des parties historiques, des conseils d’humains, et la méthode statistique de Monte-Carlo) et par renforcement (en jouant contre lui-même). En mars 2016, il bat Lee Sedol, un des meilleurs joueurs mondiaux (9e dan professionnel), le 27 mai 2017, il bat le champion du monde Ke Jie.
En octobre 2017, DeepMind dévoile AlphaGo Zero fondé sur une architecture simplifiée et n’utilisant plus ni la méthode de Monte-Carlo, ni des connaissances humaines. Il bat AlphaGo 100 à 0 après 21 jours à jouer contre lui-même.
Néanmoins, le jeu de Go et des échecs sont des jeux déterminés à informations complètes et parfaites (tous les joueurs disposent à tout moment des mêmes informations pour effectuer leurs choix, chaque joueur joue à tour de rôle (imparfaites si les joueurs jouent en même temps ce qui crée une incertitude).
Les différents types de jeu en fonction de la combinatoire, hasard, informations accessibles

Il y a une classification des jeux selon qu'il y ait un aspect combinatoire (joueur peut choisir parmi plusieurs options), le hasard et l'information.
Un jeu où un joueur n’a pas accès à la totalité des informations est un jeu à informations incomplètes. Un jeu intégrant du hasard est un jeu mixte (au lieu d'un jeu déterminé).
"Les lignes A et B correspondent aux jeux où le hasard n'intervient pas, ces jeux déterminés peuvent être à information complète ou non. Les lignes C et D correspondent aux jeux mixtes où le
hasard est associé à l'aspect purement combinatoire des jeux déterminés. Les lignes E et F n'ont pas de sens pratique dans le domaine des jeux. Les lignes G et H correspondent aux jeux de pur
hasard.
01 - Les jeux déterminés à information complète (dames, échecs, jeu de go)
02 - Les jeux déterminés à information incomplète (Attaque, bataille navale)
03 - Les jeux mixtes à information complète (Backgammon, Pachisi)
04 - Les jeux mixtes à information incomplète (Poker, Rami, Tantalus, mah-jong)
05 - Les jeux de pur hasard (jeu de l'oie, serpents et échelles)"
Michel Boutin, Le Livre des jeux de pions
Tout l’enjeu ( ;), maintenant est de qu’une IA soit capable de battre des humains sur des jeux mixtes à informations incomplètes … par exemple le Poker.
Poker

Ca ne s’est pas fait attendre puisqu’une IA (Libratus développé par une équipe de l’Université Carnegie Mellon) en janvier 2017 a fait face à quatre des meilleurs joueurs professionnels de Poker en No-Limit Hold’em, en terminant gagnante de 1,76 million de dollars (virtuels) et a renouvelé l’expérience. Pour réduire le facteur chance (et tester l'IA), deux règles ont été ajoutées : Les mains fonctionnaient en miroir, il n'y avait pas de tapis avant la fin.
D’autre part, la puissance de calcul nécessaire n’a pas coûté plus de 20 000 $.
Equilibre de Nash

Néanmoins, l'IA a un avantage car si elle n’a pas d’instinct, elle a appliqué une stratégie parfaite fondée sur l'équilibre de Nash (fameux mathématicien), qui a été vulgarisée dans le film "Un Homme d'exception" avec Russell Crowe.
"Pour tous les jeux dans lesquels le nombre de situations est fini, il existe un Équilibre de Nash."
L’équilibre de Nash est une stratégie qui garantit au joueur qui l’utilise, au minimum, de ne pas faire moins bien qu’un joueur utilisant toute autre stratégie.
Pour faire simple : en utilisant la stratégie de l’équilibre de Nash, vous ne pouvez perdre contre aucun joueur à long terme. L’existence de ces équilibres a été prouvée par John Nash en 1950, ce qui lui a permis d'obtenir le prix Nobel d’économie.
Cela signifie qu'en adoptant une stratégie parfaite dans le poker en appliquant l’équilibre de Nash, à long terme, ni l’instinct, ni les tells, ni l’intuition n’importent, ce que l'IA prouve ici. L'IA n'a donc aucun mérite ;)
Cela pose d'ailleurs un problème pour le poker en ligne qui doit évoluer car il est très difficile de distinguer un humain d'une IA.
Starcraft

Quelle est la prochaine étape ?
AlphaGo s’attelle à devenir le meilleur joueur à Starcraft II (jeu vidéo massivement multijoueurs) en tenant compte néanmoins des limites humaines (40 actions par minute maximum). Deepmind a réalisé un accord avec Blizzard pour lui permettre (via des API) à s’entraîner dessus.
La problématique pour DeepMind est de gérer une multiplicité d’objectifs annexes pour gagner (premier objectif) comme collecter des minéraux, la construction et l'évolution des infrastructures et des armes… alors qu’il y a plus de 300 actions de base possibles dans StarCraft II. Un premier challenge a été réalisé, Song, parmi les meilleurs mondiaux à Starcraft a gagné 4 à 0 en moins de 27 minutes contre quatre IA...
Quelques commentaires de sa part
"We professional gamers initiate combat only when we stand a chance of victory with our army and unit control skills. In contrast, the bots tried to keep their units alive without making any bold decisions." (In StarCraft, players have to destroy all of their competitors’ resources by scouting and patrolling opponents’ territory and implementing battle strategies.)
Song did find the bots impressive on some level. “The way they managed their units when they defended against my attacks was stunning at some points,” he said.
Les jeux de pur hasard : les seuls jeux où l'homme saura rester victorieux à 50/50 avec l'IA

Il reste heureusement des jeux ou l’IA ne pourra jamais battre les humains systématiquement … les jeux de pur hasard. La bataille et le jeu de l’oie seront-ils nos planches de salut ;)
IA face à des règles et des objectifs changeants, peu clairs, contradictoires ?

Pour tous ces jeux y compris Starcraft II, même si les moyens et sous-objectifs pour gagner sont extrêmement variés, il y a des règles du jeu claires avec un objectif final de gagner.
Qu'en est-il si les règles ne sont pas claires, varient avec le temps, les acteurs, que les objectifs sont variés, contradictoires ... est-ce que l'IA sera aussi bonne ?
Les réseaux neuronaux et la plupart des autres types d’IA ont besoin de règles strictes, d’un objectif clair à atteindre avec des données car l’IA apprend par rapport à cet objectif et doit calculer un écart entre ce qu’il a trouvé et l’objectif visé. Si cet objectif varie, n’est pas clairement défini, il est très difficile à l’IA de calculer un écart à réduire et donc d’apprendre.
Cela prendra encore un peu de temps pour l’IA de maîtriser des situations où il y a de nombreux objectifs à atteindre sans priorité claire entre elles, où les règles changent en cours de route ainsi que les objectifs.
Ces situations sont très nombreuses, réussir un partenariat commercial ou une négociation salariale en tenant compte des objectifs de l’entreprise, des objectifs des acteurs individuels qui peuvent être contradictoires (ex : chiffre d’affaires versus impact sur l’environnement, sur les salariés, impact à court terme versus long terme).
Faire plaisir à quelqu’un sur le long terme est d’une extraordinaire complexité pour une IA au-delà des cadeaux simples en fonction des goûts, de la culture, des valeurs, des liens que vous avez avec cette personne… Si une IA croit qu’en donnant le même cadeau à tous les anniversaires et fêtes, il fera plaisir, il se met le doigt dans l’œil ! On pourrait en faire un nouveau test de Turing, le "Gift Test" (ça sonne mieux en anglais ;) ! On mesurerait la capacité d'une IA à faire plaisir à une personne en lui faisant un cadeau.
Enfin, aujourd’hui, l’IA ne choisit pas les sujets sur lesquels il va s’améliorer, c’est l’homme qui le décide et qui le programme en conséquence (on en revient à la question de finalité que j'évoque avant).
L’IA n’est pas encore au stade de se programmer elle-même pour s’attaquer à un nouveau problème qui sort de son champ ( mais ça viendra… impatient de rencontrer la première IA philosophe).
Manque de priorisation et de bon sens de l'IA

Aujourd’hui, les réseaux neuronaux ne voient pas en perspective mais à plat. Ils ne priorisent pas les données par elles-mêmes, au départ, chaque donnée unitaire a autant de valeur qu’une autre.
L’apprentissage / machine learning va donner du poids aux différentes valeurs en fonction d’un objectif.
Pour les humains, l’univers des données est vallonné voire montagneux et non un océan plat de données, nous accorderons beaucoup de valeur à des données venant de certaines personnes, même si elles sont rares (ex : ces paroles que nos parents, grands-parents.. nous disent une fois et dont on se souviendra toujours et qui peuvent marquer notre vie). L’IA moyennise, pas l’intelligence humaine (sauf si un humain dit à une IA qu’il faut pondérer certaines données en fonction de la source.) l’IA n’a pas de jugement propre, elle lui est externe (aujourd’hui en tout cas …).
L’IA n’a pas de bon sens. C’est d’ailleurs un risque important car en croyant en son infaillibilité répétée, nous pourrions être victimes d’erreurs flagrantes.
Un exemple amusant est de tracer une ligne mixte (continue et discontinue) en cercle, cela attirerait des véhicules autonomes comme un pot de miel dans le cercle mais elles seraient incapables d'en sortir ;). Dans le quotidien, il y a un exemple concret lorsqu'il y a un obstacle infranchissable sur notre voie (par exemple un véhicule en panne) et que la route est délimitée par une ligne continue. A un moment, il y a de fortes chances que nous transgressions la règle de la ligne continue ;) Nous pourrions intégrer dans l'IA qu'elle peut transgresser des règles mais c'est ouvrir la boîte de Pandore ...
Biais de confirmation - Ex : Recrutement par des Startups RH intégrant de l’IA

Ce manque de priorisation favorise paradoxalement le biais de confirmation.
L’ IA est par essence biaisée par les données qui la nourrissent. Pour donner un exemple concret, si votre entreprise a l'habitude de recruter des hommes blancs de moins de 30 ans ayant fait une école de commerce et que vous nourrissez votre intelligence artificielle de ces éléments, il n'y a quasiment aucune chance pour que vous recrutiez une femme de plus de 30 ans ayant fait des études littéraires alors qu'elle correspondrait potentiellement beaucoup mieux à ce dont vous avez besoin.
C'est la raison pour laquelle il faut être extrêmement attentif aux start-ups qui intègrent de l'intelligence artificielle pour vous aider à recruter, car potentiellement cela pourrait favoriser un biais de confirmation et réduire vos chances d'augmenter la diversité dans vos équipes. En plus, vous seriez incapable de justifier le choix de l’IA. On appelle ça aussi le GIGO … Garbage In Garbage Out.
Faillible/hackable via de l'Adversarial AI

Un autre problème est que les réseaux neuronaux sont faillibles, il est très facile de les tromper et de les hacker comme le montrent quelques exemples ci-dessous.
Pour vous donner un exemple de risque potentiel, on pourrait imaginer que quelques panneaux de signalisation soient légèrement modifiés avec un filtre en plastique transparent invisible pour le commun de mortels, mais qui tromperait tous les véhicules autonomes. Cela pourrait être à l’origine d’une multitude d’accidents.
En plus comme ils agissent comme des boîtes noires il est quasi impossible de les déboguer comme un programme informatique traditionnel. De manière plus pernicieuse, on pourrait entraîner un réseau neuronal avec un lot de données correctes, mais en intégrant des exceptions qui pourraient servir de backdoor.
Les risques des réseaux neuronaux open-source en raison des backdoors inauditables

Prenons un exemple concret, imaginons que nous utilisions des réseaux neuronaux pour identifier des menaces de cyberattaque, vous présenterez d'un côté des exemples de cyberattaques et de l'autre des exemples qui ne seraient pas des cyberattaques pour entraîner le réseau neuronal à les distinguer.
Le problème est que si une personne / organisation malveillante ou qui veut se ménager une backdoor a introduit des exemples de cyberattaques durant la phase d'apprentissage en les faisant passer pour des actions normales, il sera quasi impossible de pouvoir le déterminer et celui qui a entraîné le réseau neuronal aura une backdoor pour infecter un système en dissimulant sa cyberattaque, car elle ne serait pas détectée par l'intelligence artificielle.
Cela signifie aussi que l’utilisation de réseaux neuronaux open source peut présenter un risque de contamination, car vous ne saurez pas avec quoi il a été entraîné et s’il cache des backdoors.
Dans le domaine des spams, c’est une technique nommée "poisoning" qui peut être utilisée a posteriori car une IA va continuer à apprendre sur base des attaques reçues. Si des mails sont envoyés avec des caractéristiques qui le font passer pour un non-spam ou inversement alors que c’est l’inverse, il peut contaminer l’apprentissage et cela crée une porte d’entrée. Ces techniques fonctionnent avec toutes les IA (qui apprennent). Dans le cas des spams, on utilise en général des réseaux bayésiens. Le problème des réseaux neuronaux est qu’ils sont très difficiles à auditer..
Des solutions pour expliquer les réseaux neuronaux et accélérer l'apprentissage
Rendre explicable un réseau neuronal - Mission impossible ... Peut-être pas !
Les réseaux neuronaux sont très bien adaptés lorsqu'on a une très grande quantité de données et que les informations déduites par cette intelligence artificielle sont facilement vérifiables par un être humain (comme en cryptographie avec des clés publiques / privées où il est très long à déchiffrer un code si l'on n’a pas la clé et très rapide si l'on a la clé. Dans cette analogie, la clé est l’explication rationnelle de la décision )
En revanche, ils ne sont pas du tout adaptés lorsque nous devons utiliser ces données pour prendre une décision majeure et que le résultat est difficile à vérifier par l'être humain.
Pour faire face à ce problème, il y a plusieurs solutions (en dehors d’utiliser des « Explainable AI »).
La première approche est de les tester via les programmes type bug Bounty (des hackers "white hat" testent sous toutes les coutures l'intelligence artificielle).
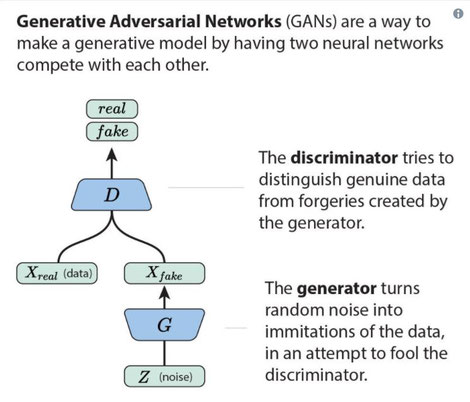
Mais on peut aussi utiliser l’IA pour tester l’IA, c’est un champ nommé Adversarial AI, qui a pour objectif notamment de trouver les failles de cette IA et de l’améliorer. On crée alors des Generative Adversarial Networks (GANs), qui vont créer un nombre innombrable de simulations qui seront testées par le premier réseau neuronal.
Cela signifie néanmoins que le Generative Adversarial Networks soit à même de classifier de la bonne manière pour que son résultat puisse être comparé à celui du réseau neuronal initial. C’est la technique utilisée par AlphaGo en jouant contre soi-même.
Démarche avec l'Adversarial AI / IA

On peut utiliser aussi le GAN (Generative Adversarial Networks) pour expliquer un réseau neuronal.
Cette technique permet d’entr’ouvrir la boîte noire en réalisant de la rétro-ingénierie.
La technique est d’intercaler une phase explicative entre la phase d'apprentissage et la phase d'exécution.
Pour cela, il faut partir d’une base classifiée par multi-critères, par exemple on va avoir une base qui sera classifiée selon des critères permettant de classifier si c’est un chat ou non, pour tenir compte des exceptions, on peut pour chaque critère donner une probabilité et utiliser des critères excluant la possibilité que c'est un chat.
Exemple :
- Critère 1 – a des poils ou pas (Si non : 90% de chances de ne pas être un chat)
- Critère 2 – est de couleur rose, bleue,… ( Si oui, 95% de chances de ne pas être un chat)
- Critère 3 – a une laisse ( Si oui, 80% de chances de ne pas être un chat)
Pour chaque branche, on a au moins un exemple d’image mais idéalement il en faudrait des milliers au minimum.
On fait passer chaque image dans le réseau neuronal, et cela nous permet de savoir quels critères sont utilisés par le réseau neuronal avec un niveau de probabilité. Si les critères sont divisés à 50% environ, cela signifie que ce n’est pas un critère utilisé par le réseau neuronal et on peut élaguer.
Utilisation Random Forest comme input d'un réseau neuronal pour le rendre explicable

On a ainsi construit l’arbre de décision du réseau neuronal avec des critères qui ont du sens pour les humains.
Ayant une base classifiée, nous pouvons aussi un cran plus loin et apprendre au réseau neuronal sur base de ses erreurs et le retester avec une nouvelle base classifiée…
On peut même combiner cette méthode avec la technique des random forest (ou forêt d'arbres décisionnels), qui va créer un très grand nombre d'arbres décisionnels de manière aléatoire. Pour chaque feuille de l'arbre, il faut néanmoins avoir des images (ou une matrice de données) entrante dans le réseau neuronal.
En passant à travers le réseau neuronal on pourrait calculer l'écart entre un arbre (qui symboliserai les règles implicites du réseau neuronal) et le résultat du réseau neuronal. L'arbre se rapprochant le plus des outputs du réseau neuronal serait la meilleure représentation de réseau neuronal.
On peut même imaginer un système d'apprentissage par backpropagation, où de nouveau random forest seraient créés sur base des écarts entre la vague précédente de random forest et les résultats de réseaux neuronaux (ainsi que des écarts entre arbres).
Génération automatique de données via les réseaux neuronaux

Avec le GAN, la création d’images pourrait être issue directement de la classification. Les couches cachées de notre réseau neuronal (par exemple, la forme, la couleur, la taille relative entre les membres de son corps…) pourraient d’ailleurs coïncider avec un nœud sur l’arbre décisionnel.
Le GAN créerait alors des images « chimériques » ou « coquecigrue » par exemple en décomposant une image existante, la transformant, la détourant, cachant des parties (oreilles, pattes, face…) en caractérisant chaque image.
Il est déjà possible de faire ce type de test comme le montre le site Pix2Pix qui crée une image de chat à partir d’un dessin à la main (le dessin n'est pas mon fort ;).

Vous pourriez encore plus facilement créer cet arbre sur le plan décisionnel avec des données structurées, par exemple si vous utilisez un réseau neuronal pour scorer des dossiers de crédits.
a. Vous pouvez prendre un dossier et vous faites varier (en utilisant un GAN par exemple) une multitude d’informations, ex : Banque, prénom, âge, ville …
b. En fonction des variations des décisions de crédit données par le réseau neuronal initial, vous pouvez reconstituer un arbre de décision (pas nécessairement exhaustif, mais avec l’IA vous avez la possibilité de prévoir beaucoup de cas).
c. Cela vous permet aussi de calculer des effets de seuil, de basculement et de vérifier les biais (ex : sur le prénom ou nom, l’adresse…).
Dans le cas où le pourcentage de chaque option correspond de manière significative sur le plan statistique à l'équiprobabilité (donc s'il y a deux options, à 50% +/- marge d'erreur liée à la taille de la population testée), cela signifie que cette branche n'est pas un critère et peut être éliminé de l'arbre de décision.
La limite néanmoins est que les règles que vous allez tester sont une approximation des règles dans le réseau neuronal. Si le réseau neuronal utilise les trois premières lettres d’un prénom, pour faire un calcul de scoring et que vous ne le testez pas, vous ne pourrez pas le décrire dans les règles. D’autre part, vous n’allez pas tester a priori des critères qui n’ont aucun sens pour vous (ex : la 3ème lettre du prénom, le numéro de l’adresse et le 4ème chiffre du code postal)
Accelérer le processus d'apprentissage avec les réseaux neuronaux vectoriels

Je propose aussi une autre démarche (c’est hardi, il y a de fortes chances que quelqu’un y ait déjà pensé depuis des lustres mais ne sait-on jamais). Je serai heureux d’avoir le retour de celles et ceux qui connaissent les réseaux neuronaux.
Aujourd’hui, le réseau de neurones entrant (image d’un chat par exemple) est une image matricielle comme une image bitmap décomposée en pixels RGB (Red Green Blue). C’est une image qui pèse bien plus lourd (à l’image des Bitmap) que d’autres images jpg qui utilisent notamment des algorithmes pour compresser l’image (avec perte pour jpg).
L’objectif est de transformer cette image composée de points en image vectorielle. L’image vectorielle est composée d'objets géométriques individuels, des primitives géométriques (segments de droite, arcs de cercle, courbes de Béziers, polygones, etc.). Chaque point dans une image est calculé par des fonctions de manière continue et non discrète. Ainsi la qualité de l’image n’est pas affectée si l'on agrandit une image à la différence d’une image fondée sur des pixels.
Exemple en transformant une courbe (sinus) en fonction (développement limité)
Imaginons pour simplifier que j’ai une image représentant une partie de courbe sinusoïdale soit la fonction y=sin(x). On peut la représenter par une courbe (x entre -1,4 et 1,3) dans une matrice 28*28 points.
Comme toute fonction, il est possible d’en réaliser un développement limité qui transforme une fonction quelconque en une fonction polynomiale (du type y= a+bx+cx^2+dx^3+…) qui approxime la fonction au voisinage d’une valeur, ici 0.
Les développements limités sont d’ailleurs utilisés par les calculatrices depuis la nuit des temps car ils sont beaucoup plus simples à calculer que la fonction elle-même.
Ici, le développement limité (dl) d’ordre n de sinus est de y=x-x^3/(2*3)+x^5/(2*3*4*5)-…(-1)^n*(X^(2n+1)/(2n+1)! + ε ( sachant que ε = epsilon, valeur négligeable = x^n * ε(x))
soit pour un dl d'ordre 3 de la fonction sinus au voisinage de 0 : y= x- x^3/(2*3) + ε
Avec cette solution on passe d’une matrice de 784 points à une matrice de 4 points (les facteurs de x).
Je fais ici bien sûr quelques raccourcis car d’une part, il y a des calculs à réaliser pour utiliser cette matrice de 4 points (élever chaque chiffre à une puissance de x) et toutes les images ne sont pas facilement vectorisables et leur poids peut être supérieur à celui de l’image initiale non vectorisée en fonction de la complexité de l'image (son entropie de Shannon).
L'intérêt de réduire la taille de cette matrice est d’accélérer les calculs et aussi de créer de nouvelles structures de réseaux neuronaux.


D'une matrice de 784 points à une matrice de 4 points ;)

Vectorisation d'une image
Dans l’exemple ci-dessous, je suis parti d’une image jpg que j’ai vectorisée (sous format SVG). La qualité est moins bonne, et le poids beaucoup plus élevé (10 fois – 1,5 MB). Néanmoins, si l'on réduit la qualité et on le met en deux couleurs, la taille est de 40k (et si l"on agrandit cette image, on ne perd plus en qualité).
On pourrait utiliser des traitements pour simplifier l’image de départ afin de réduire le nombre de points. D’autre part, si l'on part d’une image vectorielle, le poids est bien inférieur à une image bitmap voire jpg (en fonction de la complexité de l’image et de sa représentation sous forme de formules).
Image Initiale en JPG (133ko)

Pour des données qui ne constituent pas des images, on peut utiliser d’autres formules mathématiques qui peuvent être similaires à celles utilisées pour compresser des données (Zip, RAR...).
Plus l'entropie de Shannon d'une matrice de données est faible (moins les données sont aléatoires), plus la taille de la matrice de fonctions sera réduite (comme la matrice 4*1 correspondant au développement limité du sinus) et donc plus li est intéressant d'utiliser cette méthode plutôt que la matrice originelle.
Nous verrons quel sera l'avenir des réseaux neuronaux vectoriels et s'ils complètent utilement les nombreux autres réseaux neuronaux dont convolutionnels.
Image en SVG (1,5 MB)

et en 2 couleurs - 40 Ko
Conclusion
Les réseaux neuronaux existent depuis belle lurette, mais la puissance de calcul et la parallélisation massive des ordinateurs et la disponibilité de nombreuses données ont permis l'explosion de ces usages (qui a aussi permis le développement du deep learning).
Dans des domaines comme la perception (reconnaissance vocale, d'images...) ou pour donner des "insights" non explicatifs (ex: pour signaler qu'il y a des anomalies mais sans pouvoir expliquer lesquelles, analysées dans un second temps par une intelligence humaine ou un autre type d'IA), les réseaux neuronaux sont extrêmement puissants dès lorsque le nombre de données sont massives.
Néanmoins il est essentiel de ne pas oublier leurs failles et faiblesses (quantité de données nécessaires, inexplicablité intrinsèque, faillibilité avec l'existence potentielle de backdoors indétectables, biais de confirmation ...).
La combinaison de plusieurs IA (dans l'Adverserial IA) pour tester une autre IA ou comme je le proposais pour créer un arbre de décision sont des possibilités qu'ils offrent pour réduire ces problèmes.
Enfin, il faut toujours garder un esprit critique dans l'utilisation des IA car comme pour le GPS, si l'on se repose trop dessus, on en perd le sens de l'orientation au risque de se perdre définitivement ...
Si vous souhaitez que je réalise une conference, workshop spécifique à vos métiers sur ce sujets (ainsi que IoT, Blockchain, Innovations...) n'hésitez pas à me contacter :)
Dimitri Carbonnelle - Fondateur de Livosphere - Contact
Conseil en Innovation (IA, IoT, Blockchain, Robots)
Conférences, Formation, Architecte et réalisation de projets innovants : De la recherche d'innovations, de startups à leur déploiement
Articles pouvant vous intéresser
Blockchain : Révolution ou Bulle? Facebook Coin / Libra,
CES Las Vegas 2020 : Retours IA, Robots, Résilience, transport, 5G
Innovations
Énergie,Eau, Biodiversité








